In a world where AI is revolutionizing industries, a hidden threat looms. What happens when AI learns from its own mistakes? In this project, I explored the phenomenon of ‘model collapse’, where AI models deteriorate when trained on their own outputs, a situation that could affect industries from e-commerce to finance.
Model collapse refers to the gradual degradation of AI models when they are trained on data they themselves generate. Over time, this feedback loop can cause models to lose accuracy and, in extreme cases, become indistinguishable from random guessing.
Focusing on sentiment analysis using Amazon reviews, I investigated how AI models perform when progressively exposed to generated data. Reviews were categorized as either positive (4-5 stars) or negative (1-2 stars), with 3-star reviews intentionally excluded to simplify the classification task and sharpen the focus on model performance.
I developed the project in Python using several libraries:
- nltk (Natural Language Toolkit) for preparing the dataset and tokenizing the text.
- pandas for manipulating the data.
- joblib for parallelization, ensuring the project could be completed efficiently.
- scikit-learn (sklearn) for AI model processing and evaluation.
- matplotlib for visualizing the results.
You can find the code and additional resources on my GitHub page.
Step 1: Training the Classification Model
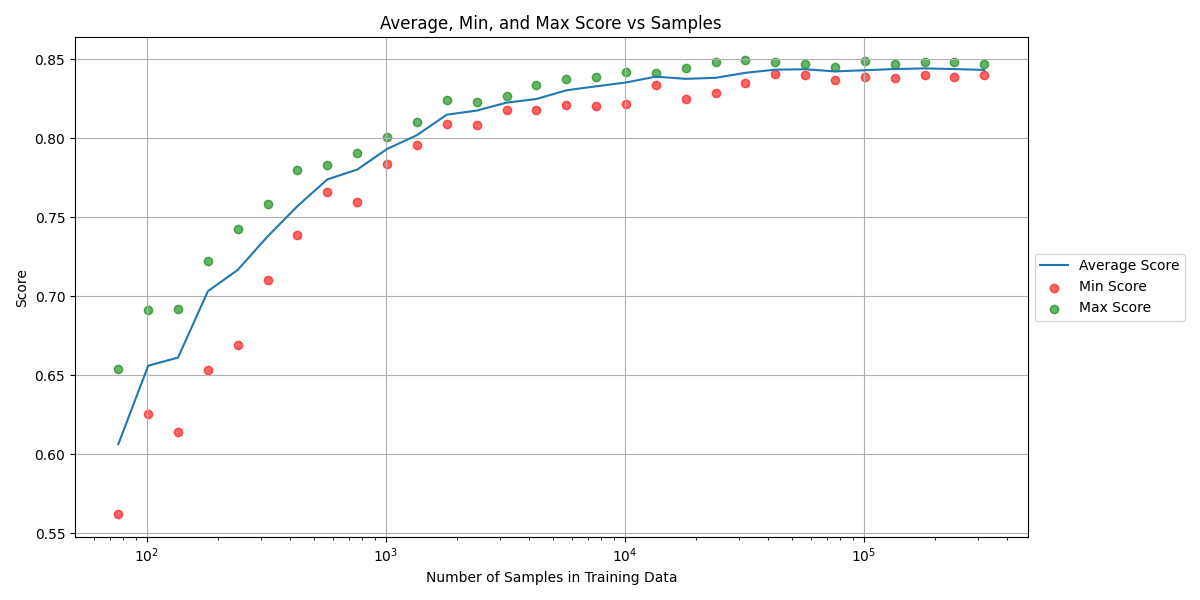
I began by developing a sentiment classification AI, testing it across various dataset sizes, ranging from 100 to 400,000 reviews. As anticipated, I observed an increase in accuracy with larger datasets, although the gains diminished as the size grew. This initial phase was crucial for establishing a baseline performance level.
With the baseline established, I moved on to simulate a worst-case scenario where the AI is trained exclusively on its own outputs—a process that leads to total collapse.
Why Sentiment Analysis?
Sentiment analysis is a practical and well documented AI application, making it ideal for testing model robustness. By focusing on Amazon reviews, I had access to a large, diverse dataset, and excluding 3-star reviews allowed me to simplify the analysis into clearer extremes: positive or negative sentiment.
Baseline Performance at different Training Sample Sizes
This graph illustrates how increasing the dataset size leads to improved accuracy, but with diminishing returns as we scale.
Step 2: Simulating a Total Collapse Scenario
Next, I set up a ‘total collapse scenario’. In this phase, after training the model normally to a range of accuracies, I let it generate its own training data, increasing the dataset size to 400,000 reviews. This is similar to someone trying to teach themselves by continually rereading and revising their own notes.
The results were striking: the model’s performance quickly deteriorated toward randomness (a score of 0.5), regardless of how well it initially performed before the collapse.
The performance graph shows a rapid and dramatic decline, represented by a steep downward curve, plummeting towards the baseline at 0.5 which is equivalent to random guessing.
Total Collapse at different start points
This graph illustrates the extreme impact of total collapse, quickly reverting my AI model to randomness regardless of the quality of the model at collapse.

Step 3: Exploring Different Collapse Rates
However a total collapse scenario isn’t particularly realistic in the real world. Rather, as people use AI models to generate content online a portion of training data for new models will inevitably be AI generated. What I wanted to know was how much generated training data can an AI model tolerate before it becomes an issue.
To discover this, I simulated various different ‘collapse rates’, where a collapse rate is the ratio of new data that is generated by AI. So with a collapse rate of 10%, for every 10 new training samples, one would be generated by the previous iteration of the model.
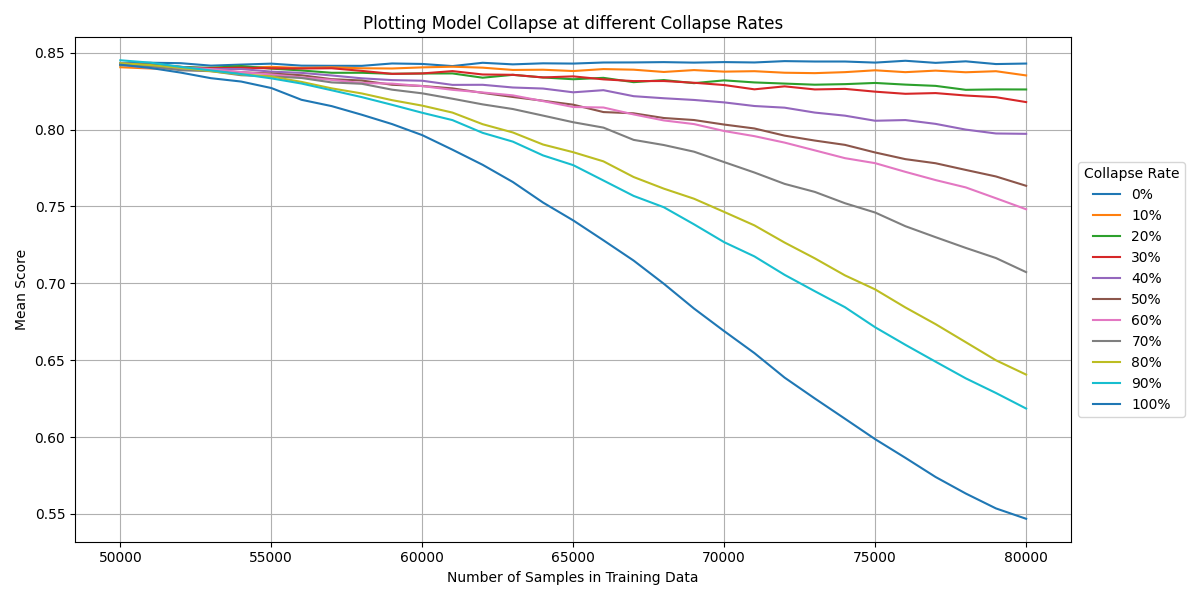
Starting with an initial dataset of 50,000 reviews, where the model had already reached a substantial level of accuracy, I gradually increased the dataset size to 80,000, incorporating self generated data at collapse rates ranging from 0% to 100% with intervals of 10%.
As expected, models with higher collapse rates experienced faster and more severe declines in performance. However it also revealed that every single collapse rate caused a degradation in performance, even as little as 10%. The initial model with a 50000 sample training dataset outperformed the 80000 sample model with 10% collapse rate, even though only 3000 of those sample were AI generated and it had 77000 human training samples. Since the model had approximately 85% accuracy at this point, only 450 samples would be ‘incorrect’ as opposed to 29550 new ‘correct’ samples.
This shocked me since I didn’t expect the issue to be so severe. However since the model was already mostly trained at 50000 samples and had hit diminishing returns, I rationalised it as the model can only get worse with new data. Curious, I decided to investigate the effects of AI generated training data on a yet unfinished mdoel.
Model Collapse at different Collapse Rates
This graph shows the varying rates of collapse on my initial model. As expected, a greater collapse rate leads to faster decline.
Step 4: Investigating Model Collapse on an ‘incomplete’ Model
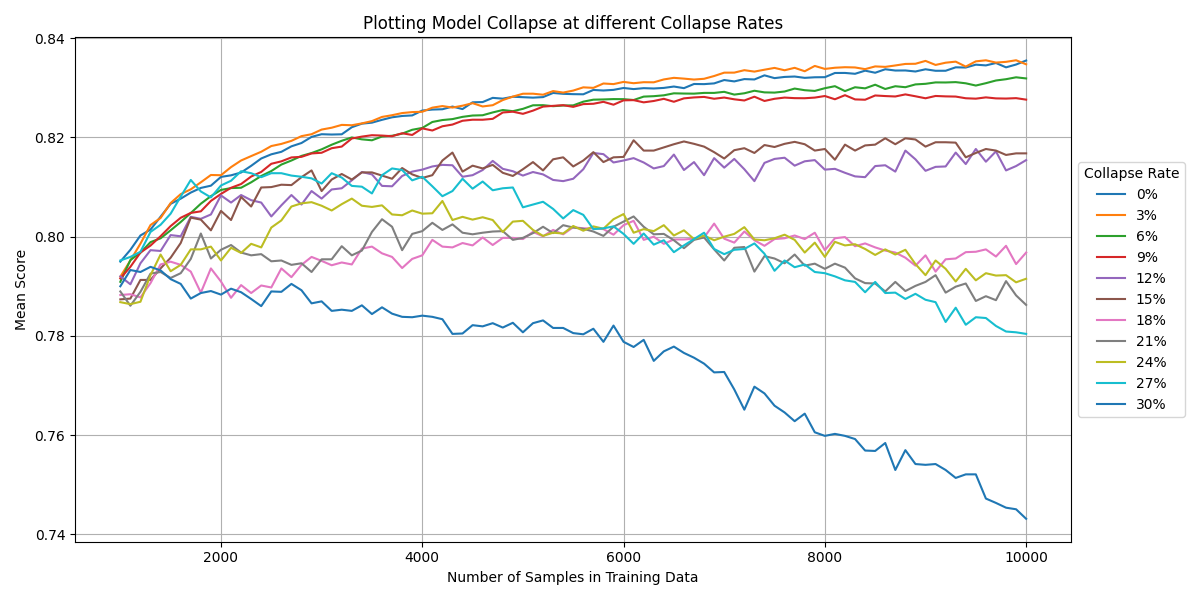
In the next phase, I focused on lower collapse rates (0% to 30% in 3% increments) and smaller sample sizes (1,000 to 10,000 reviews). During this period, the models accuracy should improve from 79% to 83% as shown with 0% collapse rate.
As shown in the below graph, a collapse rate of 18% completely offsets the new correct data. The model with a 10000 sample size training data (1620 AI generated at 18% from 1000) performed almost equal to the model with 1000 samples 0% AI generated.
Collapse rates below 18% still impacted the score, resulting in worse models than at 0%, but still performed better than the initial model with only 1000 samples. Collapse rates over 18% were worse than the inital model, making the training of a more complex model pointless beyond this point.
Interestingly, I found that a 3% collapse rate had a negligible impact on the model’s accuracy. In fact, the model’s performance nearly mirrored that of a model trained entirely on original data. This finding led me to investigate the effects of smaller amounts of AI-generated data in more detail.
Model Collapse at different Collapse Rates while training
This graph displays the effect of model collapse on a model that still has plenty of room for improvement.
Final Step: The Impact of small quantities of AI-Generated Data
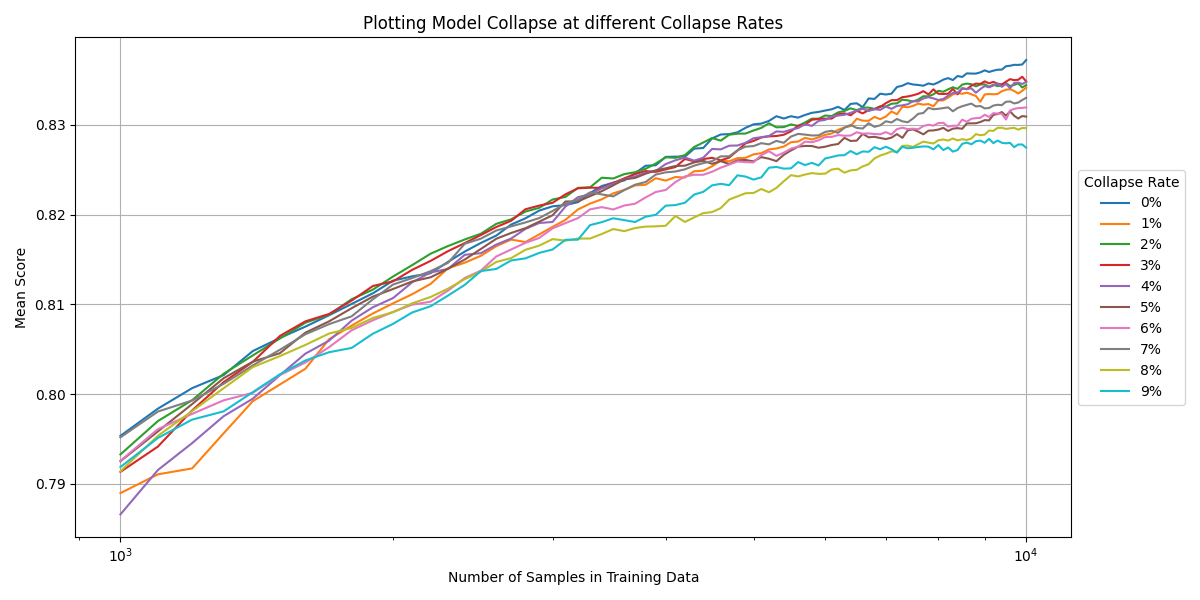
In the final stage, I wanted to investigate the effects of small collapse rates, to see if the 3% having neglible impact from the previous step was an error from small sample size. I further refined my analysis by focusing on a narrower range of collapse rates (0% to 10% in 1% increments) and cross validating my results many times, getting an accurate average.
The result was a confirmation that any inclusion of AI-generated data, no matter how small, resulted in a decline in model performance. However at small ratios (0% - 3%) the difference is small enough to be within the natural randomness caused by AI models.
For instance, the difference in accuracy between 0% and 9% model collapse from 1000 samples to 10000 sample was a mere 0.6%. This is small, but still noticable, and something that needs to be taken into account in order to maximise AI model performance.
Model Collapse at different Collapse Rates in detail
This graph illustrates small collapse rates, detailing the effects even minor amounts of AI generated data can have.
Real World Implications
In an age where AI is being increasingly used to generate content—from reviews to news articles, this project reveals a hidden danger. If companies rely online content to train their models, they could unknowingly allow AI generated data into their training datasets. This is further complicated by the difficultly in knowing if content is AI generated or not, with AI models made to classify if content was AI generated being inaccurate themselves. As a result, they could see a decline in performance despite increasing dataset size.
This degradation could affect industries such as online retail, which depends on accurate sentiment analysis; finance, where predictive models are crucial for decision making; and generative AI models which are frequently used in the modern day to create articles and art.
The findings underscore the importance of curating high quality, human verified data for training AI models. As AI-generated content becomes more prevalent, the risk of polluting new training datasets grows, and awareness of these issues is essential for developing robust, trustworthy systems.
Conclusion
This project not only deepened my understanding of model collapse but also emphasized the critical balance between leveraging AI and ensuring data integrity. The rise of AI-generated content makes it more important than ever to be vigilant about the quality of data used to train our models.
I look forward to continuing my exploration in this fascinating field. My future projects will likely expand this research into domains such as text generation and recommendation systems, where model collapse could pose significant risks.
Feel free to explore the graphs and datasets I generated throughout this project, which illustrate these findings in greater detail. I welcome any feedback or opportunities for collaboration.
You can find my code and all related resources on my GitHub page.